
Handle Data Growth With Database Scaling
Table of contents
Databases are one of the core components of any system, responsible for storing and managing data, and they significantly impact overall performance. Like any other software, databases rely on physical resources such as CPU, RAM, and storage to function efficiently.
As the amount of data grows, the demand for these resources increases. Over time, this growing data load can push a database to its limits, leading to performance bottlenecks.
Whether it's due to more users, larger datasets, or heavier processing requirements, scaling the database becomes critical to keep up with these demands and ensure the system continues to run smoothly.
Detecting Data Growth Early
Ok, then you may ask, "When should I scale?" or "How do I know if I need to increase my database's capabilities?"
Well, the answer is pretty straightforward—you just need the right inputs to guide your decision. Here are a few strategies to help:
- Reacting to User Feedback: If users start complaining about slow application performance or load times, it’s a strong indicator that your database is struggling. In this case, scaling is a must to keep your users happy.
- Analyzing Growth Patterns: Review historical data growth to estimate future needs. For example, if your database grows by X GB every two years, you might predict how much time you have before hitting limits. However, growth isn't always linear; consider potential users or traffic spikes that could accelerate data usage.
- Monitoring System Metrics: Keep an eye on CPU, memory, and disk I/O. When these approach their limits, it's time to scale. You can also use third-party tools to gain better insights and catch issues early.
For more detailed insights on when to scale your database, check out this resource: When to Scale Your Database.
Horizontal vs. Vertical Scaling: Which to Choose?
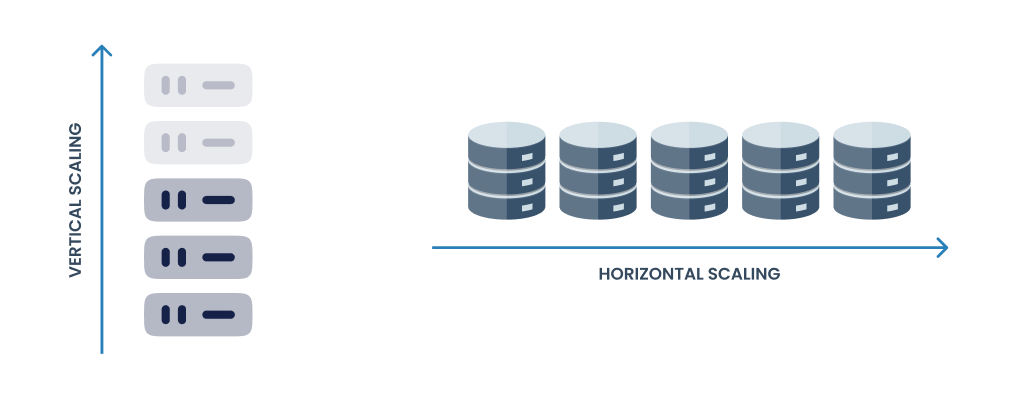
When deciding how to scale your database, you have two primary options:
- Vertical Scaling: increase the capacity of a single server by adding more resources such as CPU, RAM, or storage. This method is straightforward and often the first choice for many organizations due to its simplicity.
- Horizontal Scaling: adding more servers to distribute the load across multiple machines. This approach is often used for handling large amounts of data and high traffic loads.
The decision between horizontal and vertical scaling depends on various factors:
- Application Architecture: If your application is designed for distributed systems, horizontal scaling might be more suitable.
- Budget: Consider the long-term costs of each approach. While vertical scaling might be cheaper initially, horizontal scaling can be more cost-effective at scale.
- Growth Projections: If you anticipate rapid, unpredictable growth, horizontal scaling offers more flexibility.
- Performance Requirements: For applications requiring strong consistency and complex transactions, vertical scaling might be preferable.
In practice, many systems use a combination of both approaches, known as diagonal scaling. This hybrid strategy allows you to optimize resource utilization while maintaining flexibility for future growth.
Remember, scaling is not a one-time decision but an ongoing process. Regularly check your scaling strategy as your application grows. By staying proactive and informed about your options, you can ensure your database continues to meet performance demands efficiently and cost-effectively.
Core Scaling Techniques
Replication
Replication is a popular technique to help your database handle more traffic and stay reliable. It works by copying data from your main database (called the "primary" or "master") to other databases (called "replicas" or "slaves"). This way, you can spread out the work, especially for reading data, which takes some pressure off the main database.
There are two main types of replication:
- Master-Slave Replication: In this model, the primary database (master) handles all the writes and updates, while the secondary databases (slaves) receive copies of the data and primarily handle read operations. This improves read performance but doesn’t distribute the write load.
- Master-Master Replication: Here, two or more databases can handle both reads and writes, sharing the load evenly. This setup is more complex but provides higher availability and redundancy, as any node can serve both read and write requests.
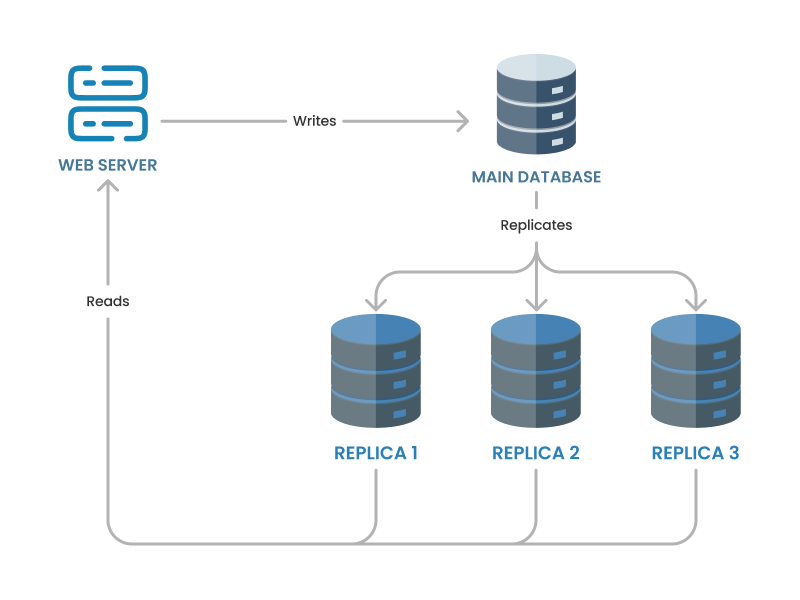
We use replication to make our system more reliable—if the main database fails, one of the replicas can take over, keeping things running smoothly. However, replication doesn’t automatically improve write performance, so it’s often paired with other techniques for scaling.
Partitioning
Partitioning is a technique used to split large databases into smaller, more manageable pieces, making it easier to handle and improving performance. Instead of having all our data in one massive table, partitioning allows us to divide it into sections, making the database faster and easier to work with.
For example, if we have a customer database, we might store customers from different regions or countries in separate partitions. Each partition has the same structure but contains different data. This is great for spreading out the workload and handling more users.
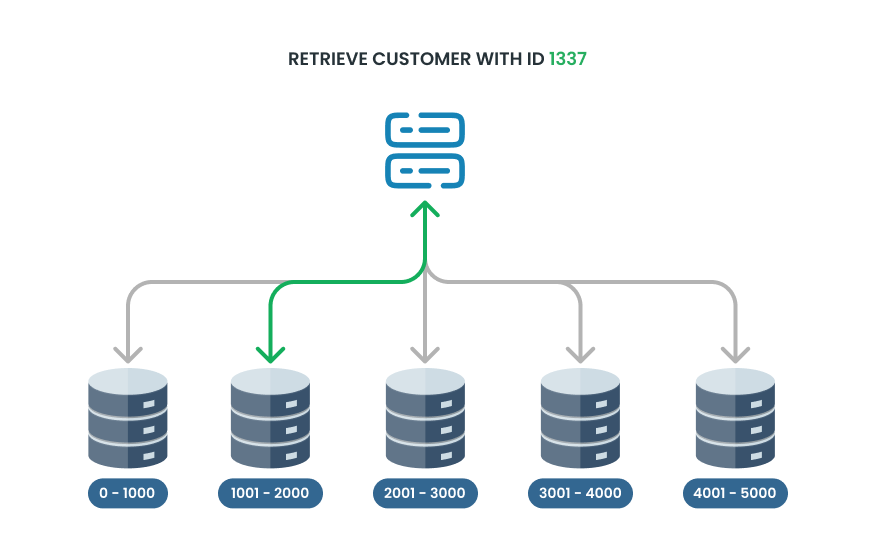
When it comes to sharding, there are a few ways we can use to partition the data:
- Range sharding: where data is divided based on a specific range of values—such as storing user IDs from 1 to 1000 in one partition and 1001 to 2000 in another. While this is straightforward, it can sometimes lead to imbalances if one range grows faster than others.
- Hash sharding: which uses a hash function to randomly distribute data across partitions. This can help spread the data more evenly but makes it harder to predict where any particular record is stored.
- Geographical sharding: in this approach, data is divided by location—such as storing users in North America in one partition and those in Europe in another. This method can reduce latency by keeping the data closer to the users it serves.
Partitioning makes the database faster by splitting it into smaller, easier to manage pieces. This means queries can be more efficient because they only need to search through part of the data. It’s also great for scaling, since we can spread those partitions across different servers, which helps reduce the load on any single machine and keeps everything running smoothly.
Making Database Scaling Easier
Alongside replication and partitioning, several other techniques can help optimize your database and make scaling easier. By focusing on these methods, you can improve performance and efficiency without constantly needing to add more resources.
Caching
Caching is the process of storing frequently accessed data in memory instead of fetching it from the database every time. With this implemented we can dramatically speed up response times for read-heavy applications.
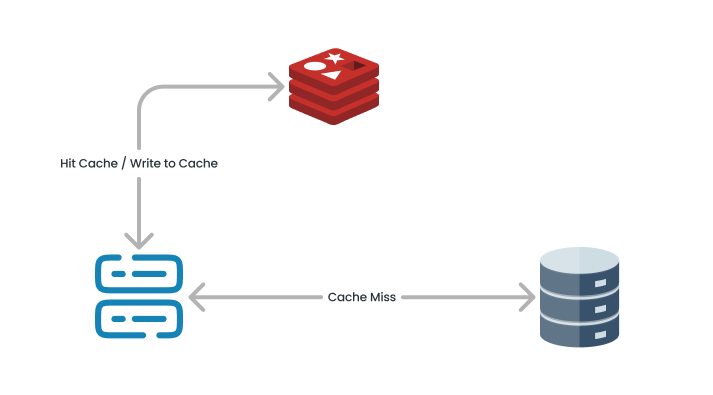
For example, in a blogging app, some articles receive significantly more traffic than others. To improve performance, we can store these frequently accessed articles in a faster, closer storage, such as an in-memory cache.
Index Optimization
Databases use indexes to quickly locate data, much like how we use a book’s index to find chapters or a dictionary’s alphabetical order to search for words. Indexes are typically created on frequently queried columns to speed up read operations, but having too many indexes can slow down write performance due to the added overhead.
When used correctly, indexes not only enhance performance but also optimize our database’s capabilities and scaling strategies. For a deeper understanding of database indexes, check out this detailed article..
Query Tuning
Sometimes the best way to handle database growth is to make sure your queries are as efficient as possible. Query tuning involves improving how queries interact with the database, ensuring they fetch data quickly and with minimal impact on performance.
Imagine a blogging app, fetching all articles by an author and then filtering the most recent ones can be slow as data grows. By tuning the query to directly fetch only the latest 10 articles, we reduce database load, speed up response times, and improve performance without needing immediate scaling.
Conclusion
Handling data growth with effective database scaling is essential for maintaining application performance and user satisfaction. Whether we're responding to data growth with vertical scaling, distributing load with horizontal scaling, or optimizing performance through techniques like replication, partitioning and caching, the key is to be proactive and adaptive.
In the end, The goal is not just to scale but to scale wisely, making the most of your resources while keeping future growth in mind.
If you have any questions, suggestions or need further clarifications, please feel free to get in touch with me. I'm here to help and support your journey in any way I can ^_^.